A practical look at how the postmeta table turns flexible metadata into expensive reads at scale.
Introduction
The wp_postmeta table underpins custom fields, product data, and SEO metadata. It enables nearly any feature a plugin or theme developer can imagine. That same flexibility creates predictable performance traps: as the number of meta rows increases, read-heavy workloads become inconsistent and slow, especially when queries filter or sort by metadata. This article details the causes of those slowdowns using common WordPress code paths and realistic examples.
Context: postmeta has changed little since WordPress 2.1 (2007). It remains an EAV-style store with a small set of indexes. Modern sites push far more data through it, so the original trade-offs are more visible than ever.
The Shape of wp_postmeta
postmeta stores attributes as key–value rows linked to a post. Ten attributes on a single post produce ten rows.
Across a catalog, that multiplier results in millions of rows even when post counts feel modest.
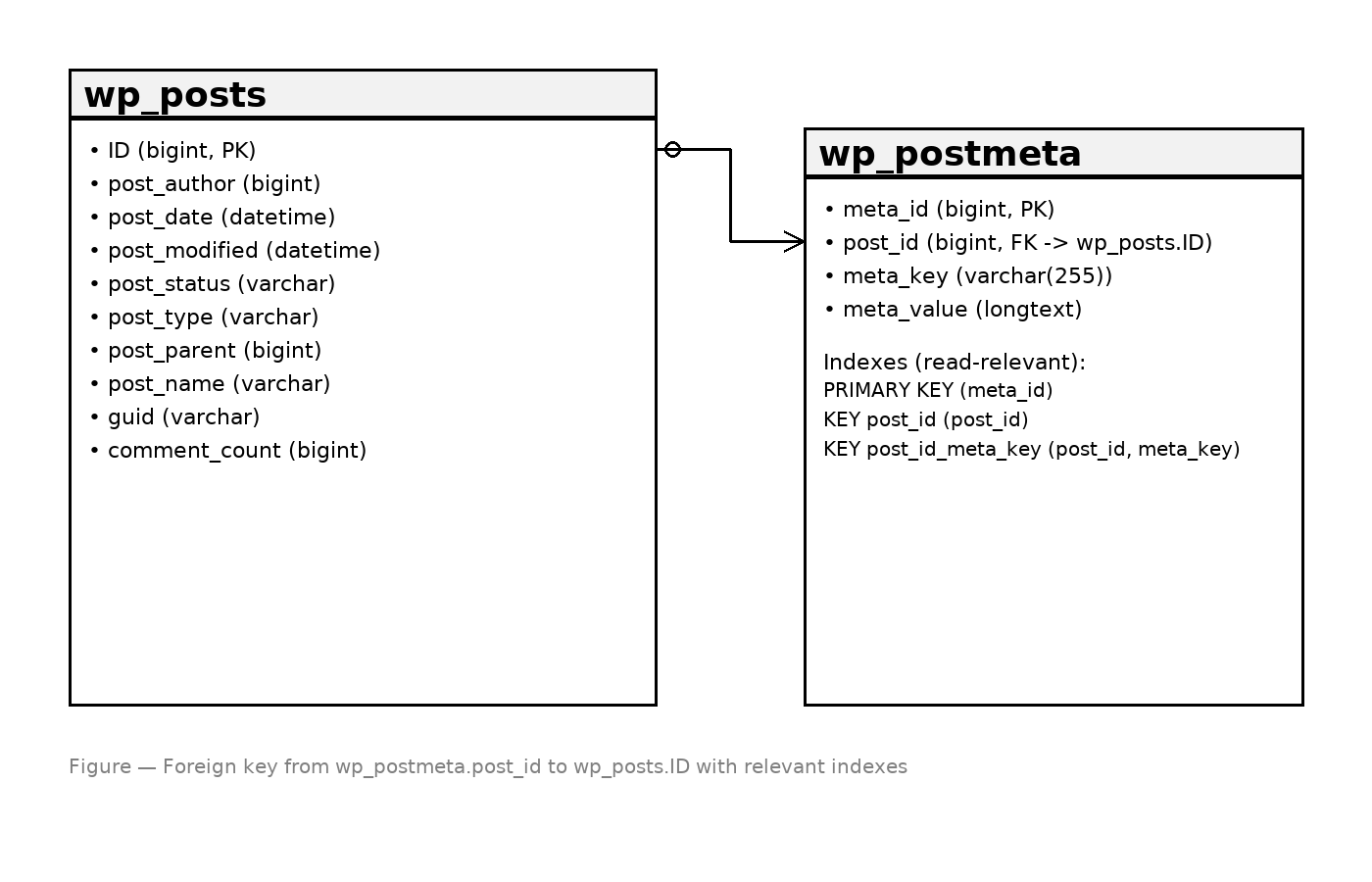
wp_posts and wp_postmetaDefault read-relevant indexes:
PRIMARY KEY (meta_id)KEY post_id (post_id)KEY post_id_meta_key (post_id, meta_key)
There is no index on meta_value. Any predicate or sort that depends on values must scan and process rows in memory, often spilling to temporary tables. That single fact drives most of the pain points below.
Scale (hardware-neutral): Small ≈ ~100k rows • Medium ≈ 2–5M rows • Large > 5M rows. The examples assume uncached requests and default WordPress indexes.
Root Causes of Read/Query Slowness
Each subsection shows a typical WordPress usage pattern, the SQL shape it produces, and why cost climbs with data size. Examples reference familiar keys such as _price, _regular_price, _sale_price, _stock_status, _sku (WooCommerce) and _yoast_wpseo_title, _yoast_wpseo_metadesc (SEO metadata).
1) EAV Expansion and Working-Set Pressure
Because each attribute is a separate row, postmeta grows far faster than posts. Once the active subset of data and indexes no longer fits comfortably in memory, otherwise routine reads fluctuate in latency. The result is spiky performance: admin lists that are snappy one moment and sluggish the next, archive pages that stall under concurrent traffic, and search/filter pages that degrade unpredictably.
- Typical symptoms: slow filtered admin screens; catalog/category pages mixing taxonomy filters with meta filters; timeouts when many users sort or filter simultaneously.
- Why it happens: more rows per post expand both data and index pages. More I/O and larger intermediate result sets follow.
2) Lookups Starting at meta_key (Without post_id)
The default composite index begins with post_id, so predicates that start with meta_key alone cannot use a leftmost index prefix. MySQL scans a large portion of postmeta to find the matching key before checking values.
// Example: find products by SKU (exact match)
$q = new WP_Query([
'post_type' => 'product',
'meta_query' => [[
'key' => '_sku',
'value' => 'ABC-123',
'compare' => '='
]],
'posts_per_page' => 20
]);This pattern can feel fine on small datasets if the key is highly selective. On medium datasets the scan becomes noticeable, and on large datasets it trends toward consistently slow under concurrency.
3) Value Predicates and LIKE Searches on meta_value
Text search across meta values forces a scan. A common example is checking whether a meta description contains a token.
$q = new WP_Query([
'post_type' => 'post',
'meta_query' => [[
'key' => '_yoast_wpseo_metadesc',
'value' => 'summer',
'compare' => 'LIKE' // e.g., '%summer%'
]],
'posts_per_page' => 20
]);
With no index on meta_value and a leading wildcard, the engine evaluates many rows for each match. Even a modest match rate translates into hundreds of thousands of examined rows on large datasets.
4) Sorting by meta_value
Sorting products by price illustrates the cost of ordering by a non-indexed value: MySQL collects qualifying rows into a temporary table, then performs a filesort. As the candidate set grows, the temp table spills to disk.
// Example: sort by numeric meta value
$q = new WP_Query([
'post_type' => 'product',
'meta_key' => '_price',
'orderby' => 'meta_value_num',
'order' => 'ASC',
'posts_per_page' => 24
]);When combined with other filters, this sort multiplies cost: first a broad scan to find candidates, then a sort over a large intermediate set.
5) Multiple Meta Conditions = Multiple Joins
More than one meta predicate introduces multiple self-joins to the same large table. WordPress aliases wp_postmeta as mt1, mt2, etc. Each extra condition triggers another pass across postmeta, increases intermediate result sizes, and raises the chances of temporary tables and grouping steps.
AND relation (common catalog filter)
$q = new WP_Query([
'post_type' => 'product',
'posts_per_page' => 24,
'meta_query' => [
'relation' => 'AND',
[
'key' => '_price',
'value' => [20, 50],
'type' => 'NUMERIC',
'compare' => 'BETWEEN'
],
[
'key' => '_stock_status',
'value' => 'instock',
'compare' => '='
]
]
]);SQL shape (simplified):
SELECT p.ID
FROM wp_posts p
INNER JOIN wp_postmeta mt1 ON (p.ID = mt1.post_id)
INNER JOIN wp_postmeta mt2 ON (p.ID = mt2.post_id)
WHERE p.post_type = 'product'
AND p.post_status = 'publish'
AND (mt1.meta_key = '_price' AND CAST(mt1.meta_value AS DECIMAL(10,2)) BETWEEN 20 AND 50)
AND (mt2.meta_key = '_stock_status' AND mt2.meta_value = 'instock')
GROUP BY p.ID
LIMIT 24;- Cost drivers: multiple passes over a large table; casting from
longtextfor numeric comparisons; grouping to collapse duplicates introduced by joins. - Scaling: fast–moderate on small datasets; slow on medium; very slow on large, especially during peak traffic.
OR relation (wider fan-out)
$q = new WP_Query([
'post_type' => 'product',
'meta_query' => [
'relation' => 'OR',
['key' => '_sku', 'value' => 'ABC-123', 'compare' => '='],
['key' => '_barcode', 'value' => '999000111', 'compare' => '=']
]
]);OR conditions widen candidate sets and usually require temporary tables for union and deduplication. On large datasets this is frequently the slowest variant of multi-meta filters.
NOT EXISTS (negative matches)
$q = new WP_Query([
'post_type' => 'product',
'meta_query' => [[ 'key' => '_sale_price', 'compare' => 'NOT EXISTS' ]]
]);
The typical plan left-joins candidates to postmeta and checks for NULL. If candidates span a large portion of the catalog,
the join pressures postmeta heavily and becomes slow.
Nested relations (3–4+ keys)
$q = new WP_Query([
'post_type' => 'product',
'meta_query' => [
'relation' => 'OR',
[
'relation' => 'AND',
['key' => '_price','value' => [20,50],'type' => 'NUMERIC','compare' => 'BETWEEN'],
['key' => '_stock_status','value' => 'instock']
],
[
'relation' => 'AND',
['key' => '_sale_price','compare' => 'EXISTS'],
['key' => '_sku','value' => 'ABC-123']
]
]
]);Every branch adds at least one more self-join. OR branches increase candidate volume and force deduplication; AND branches require intersection. Both inflate temporary tables and grouping work.
6) Large Serialized or JSON Values
Meta keys that store large serialized arrays or JSON blobs increase I/O even when filters only check meta_key.
Moving large values through the join path expands memory use, slows scans, and increases the chance that temporary tables spill to disk.
7) Interactions That Amplify Cost
- Mixing taxonomy filters with meta filters: a broad taxonomy match followed by meta filtering produces large intermediate joins.
- Sorting and filtering together: first a scan to find candidates, then a filesort on
meta_value—two expensive phases. - Heterogeneous data types in
meta_value: numeric and string values under the same key force casts and prevent any efficient comparison path. - Collation mismatches: joining across different collations increases CPU cost and can block index use on text columns elsewhere in the plan.
Relative Performance Impact
| Pattern | Small (~100k) | Medium (2–5M) | Large (>5M) |
|---|---|---|---|
Single meta_key lookup (high selectivity) |
Fast | Slow under concurrency | Consistently slow |
meta_value LIKE search |
Fast–moderate | Slow | Very slow |
Sort by meta_value |
Moderate | Slow (temp tables) | Very slow (disk spills) |
| Two meta conditions (AND) | Moderate | Slow | Very slow |
| Two meta conditions (OR) | Moderate–slow | Slow–very slow | Very slow |
| Nested meta conditions (3–4 joins) | Slow | Very slow | Very slow (high variance) |
These are hardware-neutral, uncached expectations assuming default indexes.
What Shows Up in Query Monitor
- High “rows examined” despite a small final result set.
- Temporary tables (and occasionally “Using temporary; Using filesort”).
- Multiple joined aliases of
wp_postmeta(mt1,mt2, …) on filtered admin/product screens.
Summary
wp_postmeta delivers flexibility by storing attributes as key–value rows. That design pushes heavy read costs onto MySQL whenever queries filter or sort by values, or when multiple meta conditions are combined. As row counts pass a few million, the lack of value-based indexing, repeated self-joins, and large intermediate sets turn common tasks—like filtering a catalog by price and stock or sorting by price—into consistently slow operations. Understanding these mechanics makes it straightforward to spot risky patterns in code and anticipate how they will behave as data grows.